

Un po’ di storia
Data base è un termine introdotto per la prima volta nel 1963 da Kenneth Swanson in un memo tecnico intitolato “Development and Management of a Computer-centered Data Base” [1]. Nei primi anni ’70 le due parole sono state unite per formare il neologismo ben noto base dati. A proposito, il primo sistema di gestione di basi dati è stato sviluppato negli anni ’60. I primi modelli di basi dati erano il network-based e quello gerarchico. Quest’ultimo fu adottato da IBM come base per IMS. Fu un ricercatore IBM, Edgar Frank “Ted” Codd, a definire nel 1970 il modello relazionale [2], ma il primo prodotto commerciale IBM basato su quel modello apparve solo nel 1980. Da allora, non è stato sviluppato nessun nuovo modello. Naturalmente, i ricercatori hanno continuato a migliorare il concetto di base dati introducendo le basi dati distribuite, le basi dati orientate agli oggetti e — recentemente — le basi dati XML e le basi dati ibride, come la versione 9 di IBM DB2, ma tutti queste basi dati possono essere implementate aggiungendo nuove funzionalità a una base dati relazionale, quindi non c’è stato nulla di nuovo nella modellazione dai tempi degli anni ’70 (per ulteriori informazioni sulle basi dati, potete consultare Wikipedia).
Sulle relazioni
Nella vita reale tutto è connesso al resto del mondo tramite relazioni. Ogni oggetto, creatura, individuo, evento, è in qualche modo collegato ad altri oggetti, creature, individui ed eventi. Potresti avere più di una relazione tra due elementi così come la stessa relazione potrebbe esistere tra un elemento e diversi altri. Inoltre, una relazione potrebbe essere rappresentata in molti modi diversi. Nella vita reale usiamo il linguaggio naturale per esprimere collegamenti, ma anche se il linguaggio naturale è un modo molto flessibile di comunicare, è anche un modo intrinsecamente ambiguo e multiforme di rappresentare concetti. Ad esempio, posso dire che “Giorgio è il marito di Maria” così come “Giorgio è sposato con Maria”. Ovviamente, se Giorgio è sposato con Maria, Maria è anche sposata con Giorgio. Questo è piuttosto ovvio nel caso dei matrimoni, ma non è necessariamente il caso per qualsiasi relazione. Inoltre, anche se “Maria è sposata con Giorgio”, Maria non è il marito di Giorgio ma la moglie di Giorgio. In generale, le relazioni non sono un insieme ben definito con un chiaro insieme di operatori come i tradizionali insiemi matematici. Naturalmente, se ci si concentra su una nicchia specializzata con un gergo tecnico, si può definire un modo formale per descrivere oggetti e le relative relazioni, ma questo non è vero in generale. Pertanto, se si vuole descrivere relazioni in modo che possano essere comprese da un sistema informatico, si devono sviluppare tecniche specifiche.
Un nuovo modello di base dati
Una base dati semantica è una base dati in cui un certo numero di oggetti sono collegati tra loro da relazioni semantiche. Si può rappresentarlo come un grafo dove i nodi sono gli oggetti e i collegamenti sono le relazioni. È importante sottolineare che sia gli elementi che le relazioni sono elementi della base dati. Quindi, diversamente da una base dati gerarchica o relazionale, la struttura della base dati e il contenuto della base dati non sono due concetti da mantenere separati, ma sono intrinsecamente correlati. Man mano che aggiungo nuovi oggetti, introduco anche nuovi collegamenti, quindi cambio sia il contenuto che la struttura.
Rappresentazione a rete della base dati semantica
Quindi posso interrogare sia gli oggetti che le relazioni, così come qualsiasi combinazione logica di entrambi. Ad esempio, posso cercare tutte le persone sposate, o tutti gli uomini che hanno sposato una donna il cui nome di battesimo è Maria, o semplicemente contare quanti matrimoni sono durati più di 7 anni, o quante persone si sono sposate almeno due volte.
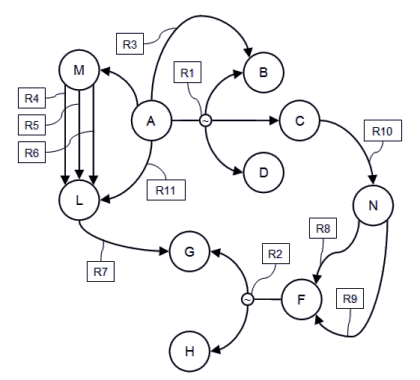
Ma come implemento una tale base dati? Prima di tutto, come rappresento le relazioni? Rappresentare oggetti è un problema ben noto. Un oggetto è solo un insieme di dati che potrebbe o meno essere incapsulato in metodi. L’oggetto più semplice è solo una coppia {nome, valore}, ma ovviamente potrei avere strutture più complesse, vettori, matrici, liste, testi semplici o con attributi, oggetti multimediali. Inoltre, possiamo avere dati semplici o dati incapsulati, cioè oggetti veri e propri. Quindi ogni oggetto potrebbe fornire sia metodi di classe che metodi di oggetti. In ogni caso devono essere oggetti reali, non classi astratte. Se voglio memorizzare una classe astratta, devo creare un oggetto che rappresenta la classe. Ma che dire delle relazioni? Per definizione non posso usare i metodi degli oggetti, poiché voglio mantenere separati oggetti e relazioni. Inoltre, potrei avere diversi tipi di relazioni: uno a uno, uno a molti, molti a molti. Dovrei essere in grado di rappresentarle tutte, in teoria. Ovviamente potrei vincolare la mia base dati a utilizzare solo relazioni uno a uno, ma sviluppare anche altre topologie mi permetterebbe di ottimizzare l’implementazione.
Topologie di relazioni
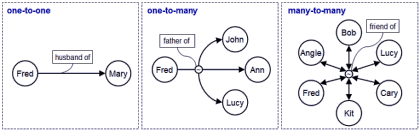
In teoria descrivere una relazione è solo una questione di collegare oggetti. Se ogni oggetto è rappresentato da un Identificatore Unico Universale (UUID), una relazione uno a uno può essere rappresentata da una struttura contenente gli UUID dei due oggetti correlati. Ovviamente, la relazione stessa sarà identificata da un UUID. Poiché stiamo rappresentando una relazione semantica, comunque, dovremmo includere anche informazioni semantiche che possono essere comprese sia dalle macchine che dagli esseri umani. Prima di tutto dovremmo essere in grado di distinguere tra elementi che agiscono come oggetti ed elementi che agiscono come relazioni. Quindi dovremmo usare un segnalino (flag) per distinguerli, e possibilmente usare lo stesso segnalino per distinguere tra diversi tipi di relazioni. In secondo luogo, dovremmo garantire che la relazione sia ben definita dal punto di vista semantico. Da notare che una relazione semantica non è necessariamente commutativa, cioè l’ordine potrebbe essere importante. Inoltre, una relazione potrebbe essere espressa in molti modi diversi e in lingue diverse.
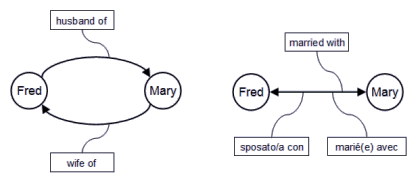
Modi diversi di rappresentare la stessa relazione semantica
Ad esempio, se “Alfredo è il padre di Anna e Giovanni” è un’affermazione vera, è anche vero che “Anna è la figlia di Alfredo” e “Giovanni è il figlio di Alfredo”, ma l’affermazione “Anna è il figlio di Alfredo” non è ovviamente vera. Se si considera anche l’intrinseca ambiguità delle lingue naturali, rappresentare un collegamento semantico in modo che possa essere compreso da una macchina è davvero una sfida. Il mondo reale è piuttosto complicato. Ad esempio, recentemente è stato dimostrato che un bambino può essere generato utilizzando il DNA di due donne e un uomo, quindi ciò genererebbe un insieme di relazioni impegnativo se applichiamo concetti standard… Comunque, come rappresentare efficacemente le relazioni semantiche è fuori dall’ambito di questo articolo. Diverse tecniche per integrare le relazioni semantiche nei base dati orientati agli oggetti [3] e nei sistemi di conoscenza [4] sono state già proposte e implementate negli ultimi dieci anni.
Un’altra domanda importante è: “Una base dati semantica è davvero diversa da uno relazionale?”, cioè, è possibile implementare una base dati semantica utilizzando un modello relazionale? Sto davvero definendo un nuovo modello o sto solo descrivendo una variante di un modello esistente? Bene, in una base dati relazionale colleghiamo i valori utilizzando i campi. Ad esempio, “Anna è la figlia di Alfredo” può essere rappresentato impostando il valore Anna nel campo FIGLIA del record Alfredo:

Una relazione in una base dati relazionale
Tuttavia, questo meccanismo non consente facilmente di aggiungere una nuova relazione, poiché devo cambiare la struttura del record. Inoltre, se cambio quella struttura per Alfredo, la cambio anche per Francesco, Maria e qualsiasi altro record che rappresenti un potenziale genitore. Ma cosa succede se ho chiamato la relazione PADRE DI invece di FIGLIA? Se la tabella contiene anche Maria, ho che “Maria è il padre di Anna”. Quindi devo separare il record di Maria dalla tabella e creare una nuova tabella. Inoltre, il fatto che sto memorizzando l’informazione che Alfredo è il padre di Anna non significa che sono interessato a memorizzare la stessa informazione anche per Giorgio o altri ragazzi nella stessa tabella. Quindi, aggiungendo sempre più relazioni alla mia base dati rischio di avere una tabella per ogni record. In pratica, la struttura di una base dati semantica cambia continuamente con il cambiare del suo contenuto. Probabilmente potrei rappresentare una base dati semantica utilizzando un’implementazione relazionale, ma sicuramente non è il modo più efficiente. Quindi, una base dati semantica richiederà probabilmente una nuova implementazione fisica per facilitare e velocizzare l’accesso ai dati e alle relazioni, la modifica e le query. Questo è fuori dall’ambito di questo articolo, ma sicuramente abbiamo la tecnologia e le competenze architetturali per svilupparlo. Per quanto riguarda i vantaggi, è mia opinione che la disponibilità di informazioni semantiche sarà sempre più richiesta nei prossimi anni, quindi il tempo è maturo per sviluppare basi dati semantiche.
Bibliografia
- [1] Swanson, A. Kenneth, “Development and Management of a Computer-centered Data Base”, Technical Memo, 1963, System Development Corp., Santa Monica (CA)
- [2] Codd, E.F., “A Relational Model of Data for Large Shared Data Banks”, “Communications of the ACM” 13 (6): 377-387
- [3] Li-Min Liu, e Halper, M.m, “Incorporating Semantic Relationships into an Object-Oriented Database System”, “System Sciences”, 1999, HICSS-32, System Sciences, 0-7695-0001-3
- [4] Tawil, A.-R. H., Gray, W. A., e Fiddian, N. J., “Discovering and Representing InterSchema Semantic Knowledge in a Cooperative Multi-Information Server Environment”, in “Database and Expert Systems Applications”, 2000, Springer Berlin/Heidelberg, 978-3-540-67978-3
Ad oggi, la vera sfida dell’informatica nel mondo del World Wide Web sono i motori di ricerca semantico-relazionali. Più delle reti neurali, i motori semantico-relazionali sarebbero in grado di individuare le relazioni semantiche tra le pagine delle rete, definire metadati in grado di rappresentarle, estrapolare gli argomenti di una conversazione su di un blog, individuare gli opinion leader, ecc.
Sono convinto che linguaggi come il Prolog, basati sulla programmazione logica e la rappresentazione logica di concetti, predicati e relazioni tra di essi, siano almeno concettualmente quanto più si avvicini ad una base di conoscenza fondata sulla semantica delle relazioni e non più sulle relazioni tra tuple di dati, o anche i vecchi dbms legacy di tipo gerarchico.
LP
Sono perfettamente d’accordo sui motori semantico-relazionali, ma questi in genere operano su dati non strutturati, come ad esempio i testi. Le basi dati sono invece dati strutturati. Il modello semantico ha in effetti lo scopo di memorizzare relazioni semantiche strutturate che possano poi essere utilizzate da altre applicazioni per vari motivi, inclusa l’interpretazione di dati non strutturati e la definizione di un contesto che possa essere utilizzato appunto dai motori semantico-relazionali.
Ivan Herman, W3C Semantic Web Activity Lead, indicated to me a couple of interesting pages about triple stores, that is RDF Triple Store Systems and ESW Wiki: LargeTripleStores.
According to Ivan’s understanding, some of these are implemented on top of relational database systems, some of them are developed as triple stores from bottom up, for example Kowari and derivatives. He thinks that it could be the case of Jena SDB and Sesame, too.